Probability of Hacks


For about the past year, I've been doing lots of research and reflection into security testing approaches I've learned over 20+ years of testing. That is, ignoring all the hype about framework this, or methodology that– what are the real nuts and bolts of how security assessments work and can we introduce some formalism into things. In order to represent strategy better in more AI/automation based approaches– we need to understand the mechanics better both formally and cognitively. I am also a wannabe mathematician– and this exercise ties directly to my phd work.
The overall point of the phd thesis work I am doing basically boils down to this:
- What people do, and more specifically how people 'think' about testing is critical towards any effort in security tooling.
- Security tooling for web security is woefully incomplete and inadequate.
- AI/ML offers us a bunch of new ways to leverage how people think, so we can create better security tooling.
But for now, ignore all that. What I want to talk about first is a hypothesis that I think functionally describes what "I know" about security assessment:
All assessment strategies should be designed to produce the highest probability of an intended outcome, as constrained by the number of assets discovered, questions asked per asset, and total time allocated for the assessment.
Which more formally breaks into a formula that looks sorta* like this:
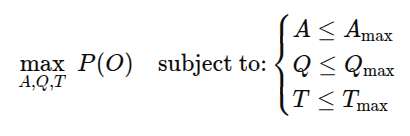
Which is effectively an optimization problem that states that the goal is to maximize the probability of success P(O), the intended outcome, which is constrained by:
- A: number of assets identified in a discovered discovered space– with A representing both depth and breadth. This would be represented as a unique strategy, as a plausible space still takes time for discovery– and those methods of discovery also take time.
- Q: number of questions (tests, tactics, payloads, scenarios) asked per asset or sets of assets. Same as discovery space, this is its own strategy with considerations for discovery questions, evasion tactics, etc... each having their own weighting as pertains to quality of ask.
- T: total time allocated for the assessment. everything takes time, there is a limit to what you can do within the agreed upon limits.
This formula should at the very least be familiar to anyone who scopes projects. We take the total number of testable assets, we apply some filter on complexity of questions we might ask to accomplish a goal, and we output some time variable to quote a customer. This should be the easy part. But what are we predicting with that? In theory: the probability of success.
Just talking about intuition–would you ever argue that having less time, asking less questions, of lesser fidelity, over less assets is likely to produce quality results? While it is true that diminishing returns exist, and too much of anything can be a bad thing– in your gut, what things increase the success of a test? Better questions, deeper understanding of assets (attack surface), more time, etc... Where this leaves me intuitively is that more is generally better, within reason. But better for what becomes the forty million dollar question.
Testing Goals
Every test has differing goals. And while the industry often throws around terms like red team, black box, purple team'd emulation... these rarely reflect the real goals of a security assessment At best these terms give a sense of a generalized expectation, at worst they are a bucket of hours not tied to a shared outcome. Good security companies have ways to address this with customers, they aren't always obvious/stated– and surprisingly there are a wide range of them. Here are some I've seen:
- Scope-based expectations:
- Find everything wrong
- Find at least one critical/high-risk issue– lows and mediums don't count
- Dissect the code and find deep architectural problems
- Map coverage against a compliance framework
- Outcome-based expectations:
- Access something internal of value
- Demonstrate how someone else might have broken in
- Perform 'stealth' testing of internal controls.
- Comparison-based expectations:
- Benchmark against other firms or their own internal teams
- Don't miss anything that a bug bounty person finds (or worse still adversary)
- Transactional expectations:
- Get paid per vulnerability
- Pray you don't find anything
Each of these expectations introduces a unique set of constraints—and those constraints fundamentally alter the probability space you’re operating in. The more clearly you understand what success looks like, the more effectively you can design your testing strategy to meet it.
Now let's talk probability
If you have a clear outcome from a customer side, you can now prioritize and align your testing strategies to optimize towards meeting that goal. Take bug bounty as a simple example. If your goal was to earn a payout**, all you need is a single accepted finding that isn't a duplicate. In this case, your testing strategy will likely focus on maximizing your odds of finding just one valid vulnerability. From a strategy perspective, you'd start with framing your probability space with questions like:
- Which vulnerability categories offer the best time-to-reward ratio?
- Which programs are easy to work with
- Can I get into a 'green field' private testing that others haven't before.
- What customer/customers are big enough to justify investing deeper time/effort?
Those external considerations play a part in your overall success strategy, but looking at it purely at a basic level– your odds of success can be described as:
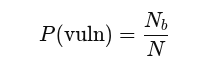
Where:
- Nb: the number of items in the category of interest (vulnerabilities),
- N: size of the total space you are evaluating.
To optimize for success, you can increase either the size of Nb relative to N, or you can simply increase the size of N. In other words, for the bug hunter, the more types of vulnerabilities you can look for effectively in a larger space, you greatly increase your odds of success.
Suppose each vulnerability is like rolling dice. You have three ways you can optimize the game to win. If each dice has six sides, it has a 1 in 6 chance of landing on any specific number. If you expand the number of dice to 10, the probability of at least one showing a 1 is about 84%. With 20 dice, that jumps to 97%. Equally, if you change your success criteria to be either a 1 or a 2, each single dice has a 30% chance of success now on it's own, and that same 10-dice roll now gives you a 98% chance. The last way you can increase your odds is to reduce the number of sides of the dice.
You can improve your chances by: adding more dice (larger test surface), expanding success criteria (broader vulnerabilities), or rolling better (more efficient).
If you think of this same problem with different success outcomes you radically change your odds. Suppose you need to find at least three vulnerabilities (i.e at least 3 dice are 1), with the same 10 dice, your rate of success drops to 15%. Even if I increase the category be more broad to "at least 3 dice are a 1 or 2" it only moves your odds to a 20% chance of success.
In the situations where "coverage" matters more, it is kind of like asking how many different rolls does it take to have each dice exercise 1-6.
Por fin
This framework isn't a simplification– it is a lens. I believe that these constraints directly map to how we make strategic decisions under pressure. We are effectively just betting with time. You don't get infinite rolls, you don't get infinite time, and not all dice are equal. Your success depends on how well you can understand the expected outcome, and then optimize your testing strategy to produce it. Every decision made during an assessment is a risk that moves you closer or further from the intended outcome.
In the next few posts, I'll be exploring how we can intentionally optimize across those three key areas of time (rate, pacing, strategy), discovering the asset space(breadth and depth), and question strategies (precision vs. volume tradeoff).
If this kind of strategic thinking resonates with you, I'd love to hear from you and follow along as I dive deeper into each domain.
*This formula should likely take into consideration weights that can impact outcomes like the speed in which a target responds, the fidelity of each question as tied to an asset, etc...
**bug bounty folk also have many reasons to do assessment. It is not fair to assume it is all just tied to money, some of it is just to have fun and or to learn or whatever. Those individual goals also impact how one optimizes/spends their time